Improving Drools Memory Performance
I was working on what appeared to be a fairly complex rule base based on EMF. The rules aren’t operating over a huge number of facts (less than 10,000 EObjects) and there aren’t too many rules (less than 300), but I was having a problem with running out of Java heap space (set at ~400 MB).
A sample rule would look like the first rule in this package.
I thought of a number of different solutions, and the Drools mailing list suggested some more:
- Creating a separate intermediary meta-model to split up the sizes of the rules. e.g. instead of (if A and B and C then insert D), using (if A and B then insert E; if E and C then insert D). (This is known as using materialized views to create summary tables.)
- Moving
eval()statements directly into theType(...)selectors. - Removing
eval()statements. Would this allow for better indexing by the Rete algorithm? - Reducing the height, or the width, of the class hierarchy of the facts. e.g. Removing interfaces or abstract classes to reduce the possible matches.
- Conversely, increasing the height, or the width, of the class hierarchy. e.g. Adding interfaces or abstract classes to reduce field accessors.
- Instead of using EObject.eContainer, creating an explicit containment property in all of my EObjects.
- Creating a DSL that is human-readable, but allows for the automation of some of these approaches.
- Moving all rules into one rule file, or splitting up rules into smaller files.
From these techniques I thought of four options.
Combining Files
Here, I would simply combine all of the rules into one file, as in this revision. The idea behind this, is that perhaps the Drools engine could not optimise the network correctly because the rules were all in different files. This turned out to be untrue.
Replacing eval(veto)
handler.veto(object) was defined as follows:
return !object.isOverridden();
I could remove this from the rules, as in this revision, as follows:
detail : DetailWire ( overridden == false )
I found out that removing this from the rules did not make a significant difference either in time or in memory. This is probably because my test models had very few model elements where overridden was actually true; thus, this restriction was not actually making any difference.
Replace eval(connectSet)
This was a much better approach. Here, connectSet(object, a, b) was essentially implemented as:
return object.getFrom() != null && object.getTo() != null && object.getFrom().equals(a) && object.getTo().equals(b);
I could merge this directly, as in this revision, into the rule:
detail : DetailWire ( from == source, to == target )
This made a huge difference in both execution time and memory usage.
Replace eval(connects)
Similar to connectsSet, this rule allowed me to select bidirectional edges. The function was written as:
return object.getFrom() != null && object.getTo() != null
&& (object.getFrom().equals(a) && object.getTo().equals(b))
|| (object.getTo().equals(a) && object.getFrom().equals(b));
This could be rewritten, as in this revision, as:
detail : DetailWire ( (from == source && to == target) || (from == target && to == source) )
I found this didn’t make as much of an effect as connectsSet. I think this is because connectsSet is unidirectional so the selects can be applied very effectively, whereas connects is essentially rewritten as an eval() condition (since it uses && and || conditionals directly).
Comparison
To compare, I made some graphs. These metrics are not very reliable, as each test was only executed once, and garbage collection was not completely accounted for; however, I think it represents a realistic collection of data for comparison purposes. The first graph compares the execution time for inferring two different models.
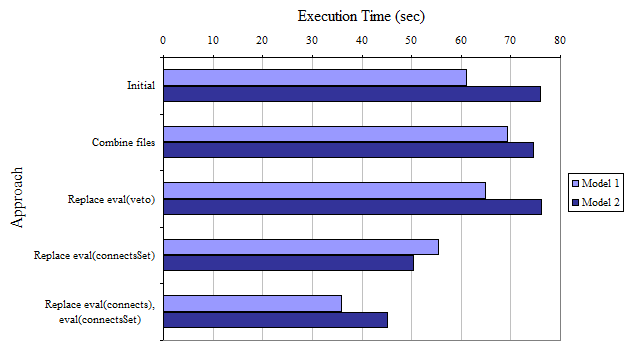
The second compares the allocated heap usage. The idea behind this is that the JVM will not allocate more heap space until it is actually necessary, but it does not reclaim allocated heap, so the maximum memory usage is definitely lower than the final allocated heap.
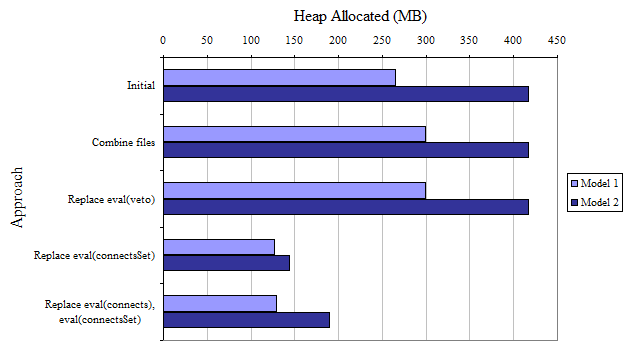
The final compares the final heap usage; that is, the amount of heap used once the inference has complete. This measure is much less reliable than the allocated heap usage, as this value is affected by garbage collection.
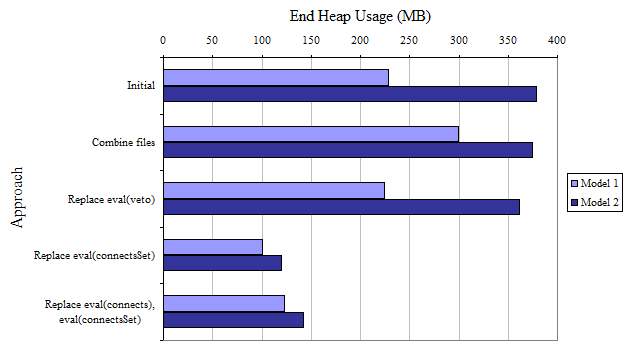
In the future these tests should be rewritten to actually keep track of the memory size over time, and the tests should execute multiple times over a wider range of models (i.e. more than two).